Deep Learning による自然言語処理

はじめに
自然言語処理とは
これから Deep Learning を使った自然言語処理についてお話しします。自然言語とは日本語や英語などの人工のものではない言語を指します。ここでは文字列で表される文章を対象とします。また例として主に英文を用いますが日本語でも基本的には同じことができます。
自然言語処理の主なタスクには
- 翻訳や文章の内容に応じたタグ付け
- 質問に対する回答 (Q and A)
- 文章の要約や含まれる感情解析
などが挙げられます。
画像の次は自然言語!
2012 年の画像の Deep Learning 革命 (ILSVRC) 以降、研究者の間では次のターゲットは自然言語処理だと大いに盛り上がりました。しかしその道のりは決して平坦なものではありませんでした。この分野では Google の寄与が非常に大きいと思います。それには次のような事情があります。
何よりもまず Deep Learning の生みの親の一人であるHinton 先生を真っ先に取り込みましたし、また自然言語処理は彼らの主要ビジネスである Web 検索サービスの生命線だからでしょう。
その結果、多くの重要な論文が Google から発表されたことに加え、実装を含めて広く公開している点も素晴らしいと思います。
Deep Learning の復習
簡単に Deep Learning について復習しておきましょう。
ニューロンモデル
Deep Learning に置けるニューロンは神経細胞の反応を模した多変数の引数を持つ非線形関数です。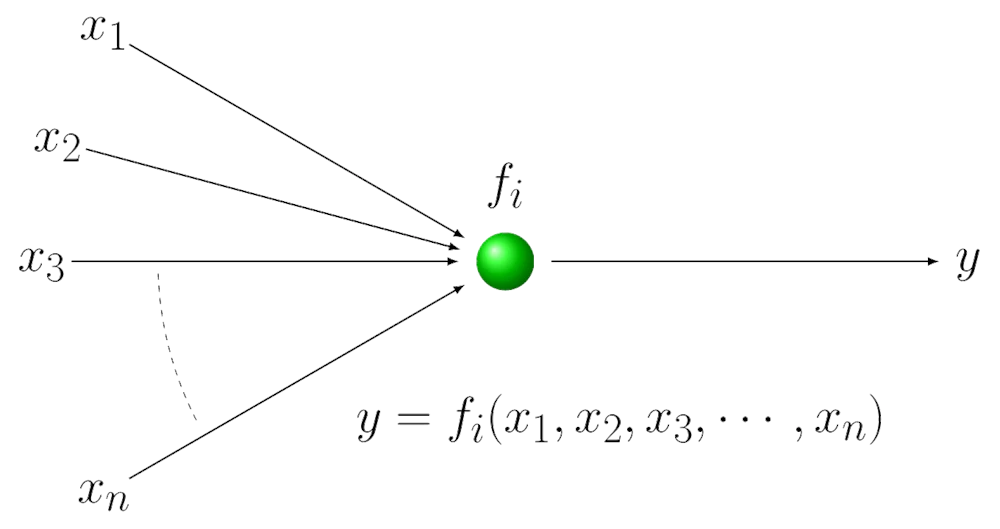
非線形関数とは次に示すように、
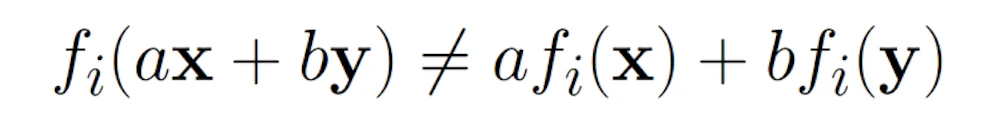
等号が常に成り立つとは限らない関数です。
この関数は内部にパラメーターを持ち形を変えることができます。
ニューラルネット
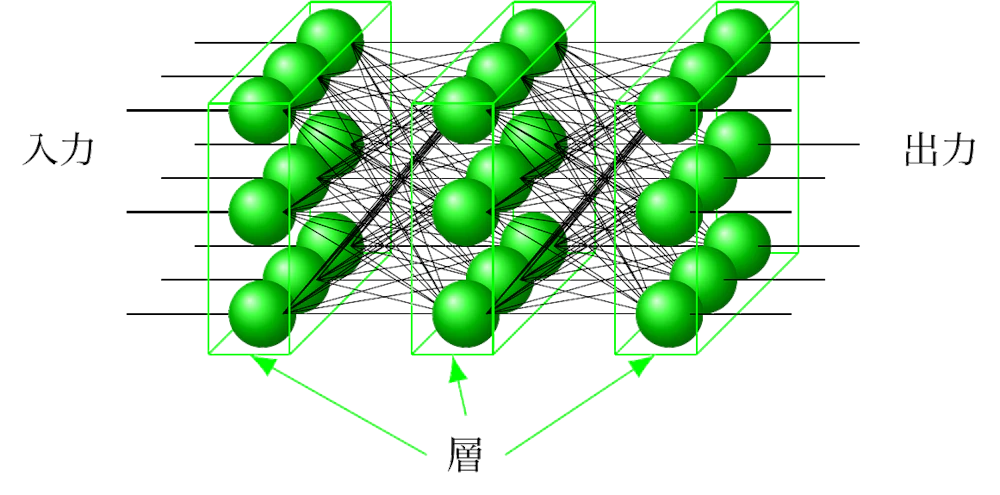
このニューロンをたくさん束ねて層を作り、層の間を結線します (シナプスに相当)。
入力に対して望ましい出力が得られるようにニューロン[latex]f_i[/latex] の形を修正していく過程を学習または訓練と呼びます。このようなニューラルネットで層の数が 4 以上のものを扱う技術を Deep Learning と呼びます。
画像分類

ニューラルネットで画像の分類を行うことを考えてみましょう。
この場合、出力の各線に推測結果の項目 (ラベル) を割り当てます。画像を構成する二次元配列の値を入力し、各ニューロンの関数の値を計算していきます。最終的に出力で一番大きな値を出した線のラベルをニューラルネットの推測値とします。
これを応用して作成したのが以前公開した Bird Classification です。
ちなみに、Bird Classification では「野鳥の画像を入力し、実際に Deep Learning を使ってその種類を推測させる」ことができます。詳しくはこちらの記事をご覧になってみてください。そしてぜひデモページで遊んでみてください。
ファインチューニング (fine tuning)
Deep Learning の学習でよく使われる手法にファインチューニングがあります。これは、既に別のデータについて学習済みのニューラルネットを用意し、最終出力層のみを新たなタスクに対応したものに付け替えます。その状態を初期値として学習を始めることにより少ない教師データでも効率よく学習が進むことが分かっています。
自然言語処理
入出力
さて、ニューラルネットの入力と出力は実数 (の配列) のみです。自然言語処理に応用しようとするとき、文章をどうやって入力するかがまず問題になります。 最初に思いつくのは文字列の ASCII コードを入力するという方法ですが、これだと単語という概念を学習させる必要があるため非常に遠回りです。次に考えられるのは単語に ID を振って実数 (整数) にしてしまうという方法です。
ところが語彙の数 m は 100,000 のオーダーで、且つ ID が一つ異なるだけで別の単語として扱わなければなりません。これは [latex]10^{-5}[/latex] の精度が必要なことを意味していますが、ニューラルネットにはこのような精度は望めません。ASCII コードの場合の [latex]10^{-2}[/latex] ですら望み薄です。
このような場合はニューラルネットの「線」を使います。まず各単語に ID (1, 2,…, m) を振ります。m 次元ベクトル (配列) を用意して ID 番目の次元だけ 1、他の次元は 0 として、このベクトルで単語を表します。これを one-hot 表現 (encoding) と言います。語彙の数 m だけ入力線を用意し、ベクトルを入力とするのです。
ただしこのままではいかにも効率が悪いですし、恣意的に決めたベクトルには「意味」もありません。
埋め込み (Embedding)
word2vec (2013)
そこで登場したのが word2vec です。
これは効率の良い単語のベクトル表現を求める手法で、入力と出力は共に one-hot 表現の次元をもつベクトルとした 2 層の浅いニューラルネットを用います。ここで、隠れ層 (中間層) のニューロンの数は特定の数 H に絞ります。H は 100 のオーダーで、後で出てくる BERT の場合は 768 に設定しています。
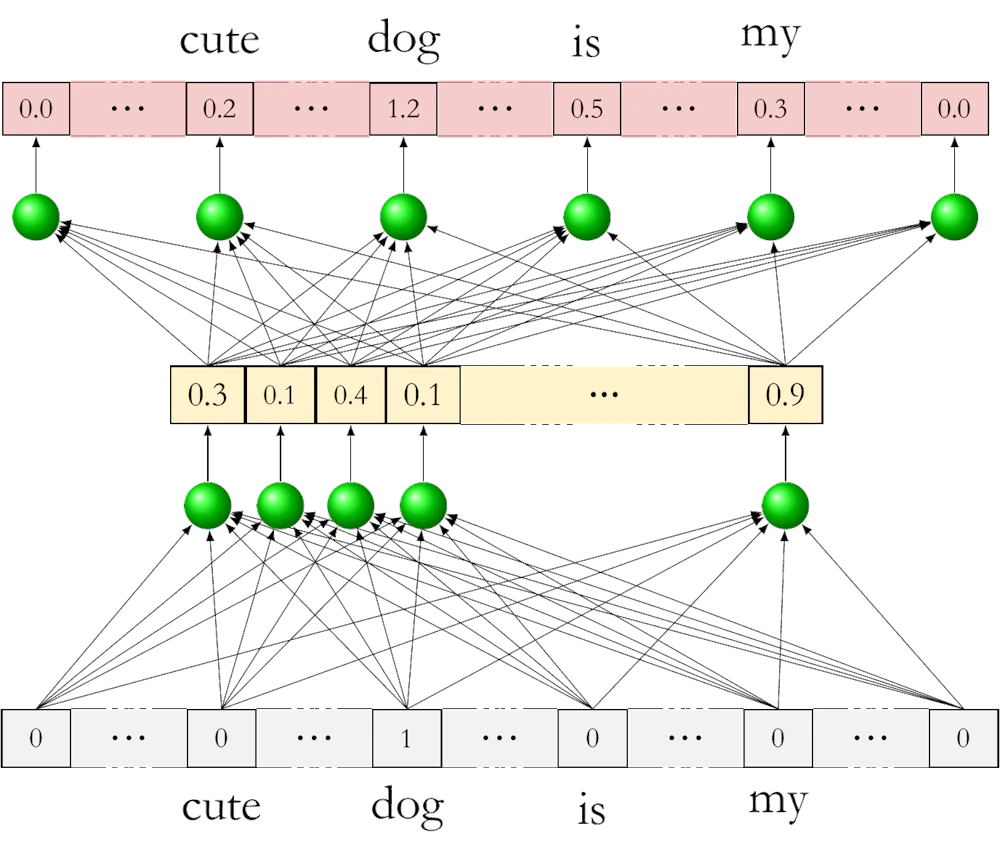
このニューラルネットを入力と同じ次元に値が出力されるように、また文章中でその単語の付近に現れる単語にも値が出力されるように学習させ、最終的に隠れ層の値を各単語のベクトルとして採用します。
この処理を単語の埋め込み (embedding) と呼びます。これによりベクトルの次元が大幅に小さくなるだけでなく面白いことに単語間で演算ができるようになります。例えば、
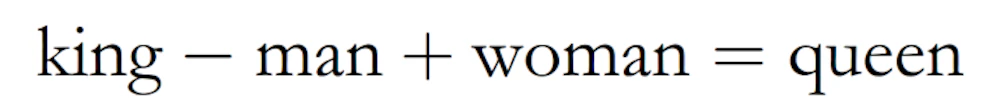
という関係が成り立つようになります。ただしここでの等号は一番近いベクトルという意味です。このように word2vec による埋め込みは単語の「意味」を反映したベクトル表現になっています。
自然言語処理固有の課題
これでどのようなものを入力とすべきかはわかりましたが、自然言語処理には様々な問題があります。
まず文章は基本的に先頭から順に単語を追って読んでいかないと意味がわかりません。例えばただ drunk とあっても意味不明ですが I have drunk a cup of coffee なら意味が分かります。
また代名詞というものが存在します。“its" や "she" などが何を指すかも先頭から読んでいく必要があります。
これに対し画像はその一部を取り出しても認識が可能です。例えばこの部分は顔だとか、この部分はタイヤだとかわかります。
すなわち文章の処理にはコンテキストが決定的に重要なわけです。
RNN (Recurrent Neural Network)
そこで考えられたのが RNN で、これは前段階の出力をコンテキストとして次の入力と共に再帰的に入力して用いるニューラルネットです。
例として英語をドイツ語に翻訳するタスクへの応用を次の図に示します。
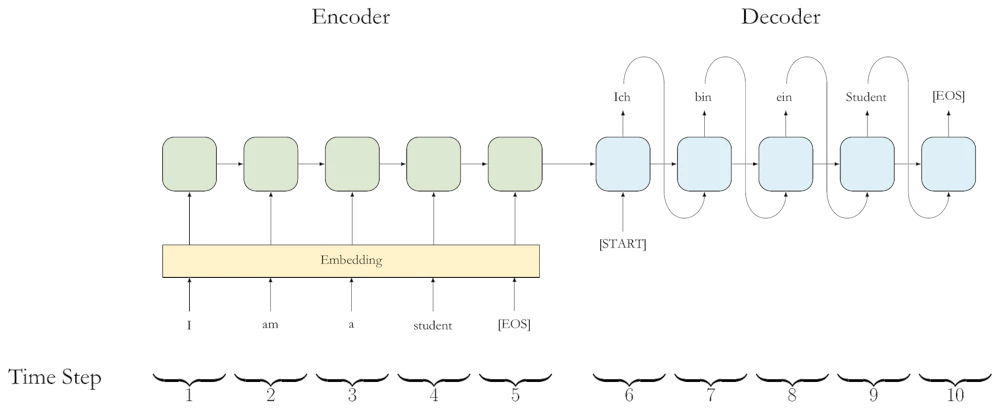
ここでは Encoder と Decoder という二種類の RNN を使っています。各ステップではそのときに入力される単語に加えて前段階の出力も入力されています。
RNN の問題点
しかし RNN にはいくつかの大きな問題点がありました。
- 先に入力した単語の情報が消えてしまう
- 長い文章になるとはじめの方に入力した単語の情報 (コンテキスト) が反映されなくなるという問題があります。これを解決するために LSTM (Long-Short Term Memory) モデルが提唱され、一頃はそれ一色になる程流行したのですが、結局本質的な解決にはなりませんでした。
- 学習にとてつもなく時間が掛かる
- RNN の処理は本質的に逐次であり、入力単語数に比例した処理時間が必要です。これは Deep Learning で大きな効果を発揮した並列化ができないことを意味します。
最初の break through
Transformers (2017)
2017 年になって RNN の問題点を解決する Transformers が提唱されます。論文のタイトルも非常に野心的です。Transformers では (self) attention を導入することで recurrent を不要にしました。これで処理の並列化が可能になりました。
attention は一種の key-value ストアで、入力の単語 (query) について各 key との類似度を計算し、それに応じた重みで value の値を足し合わせて出力とします。
self attention は、key を query そのものにした attention です。 attention 自身も学習によって更新していきます。その結果出てくる値は単語間の関連性を反映したものになります。
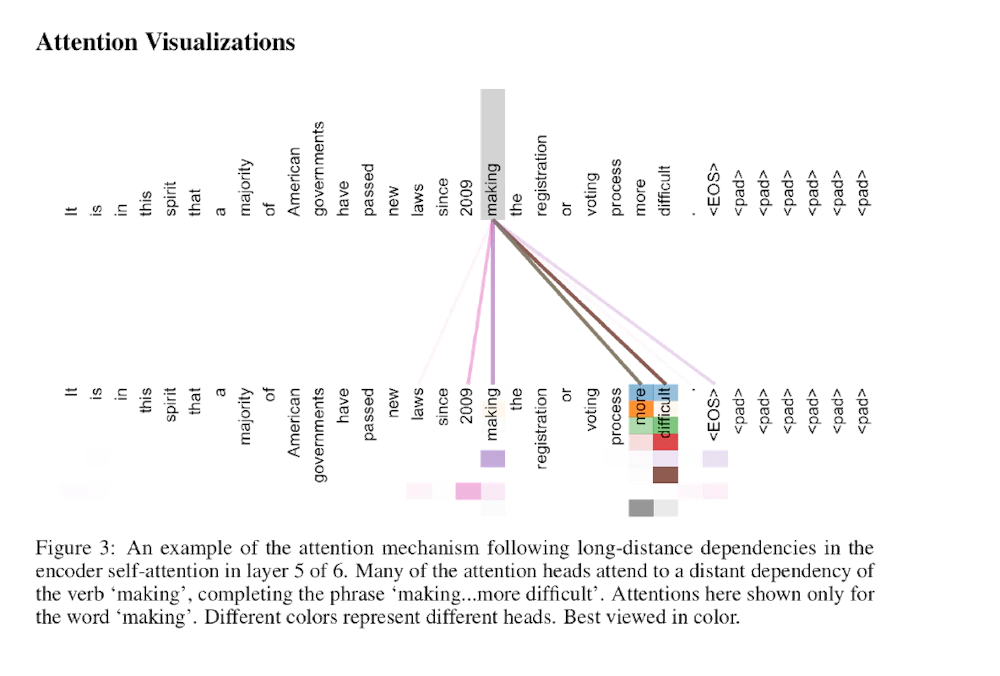
Transformers では attention によって文章のコンテキストを把握することが可能になっています。
Transformers の登場は、それ以降ほぼ全てのニューラルネットが Transformers をベースとするようになるほど画期的でした。
次の break through
BERT の登場 (2019)

BERT は Bidirectional Encoder Representations from Transformers の頭文字とされていますが、要は Transformers があって、また ELMo というシステムもあったので、子供向けテレビ番組つながりで BERT にしたのだと思います。
BERT の特長
- 文章を並列処理可能
- これは Transformers ベースのニューラルネットだからです。
- 大規模なコーパス (文例集) によって教師データ無しの事前学習を行わせる
- 教師データを必要としないのでコーパスを用意するコストが大幅に下がります。
- 個別のタスクにはファインチューニングで対応
- 自然言語処理でも画像のケースと同じくファインチューニングができるようになりました。これにより少ない教師データで効率よく学習させることができます。
- 多くの事前学習済み BERT が公開されている
- 日本語の場合でも
- 京都大学 黒橋・褚・村脇研究室
- 東北大学 乾研究室
- NICT
- など多くの学習済みモデルが公開されています。
- 日本語の場合でも
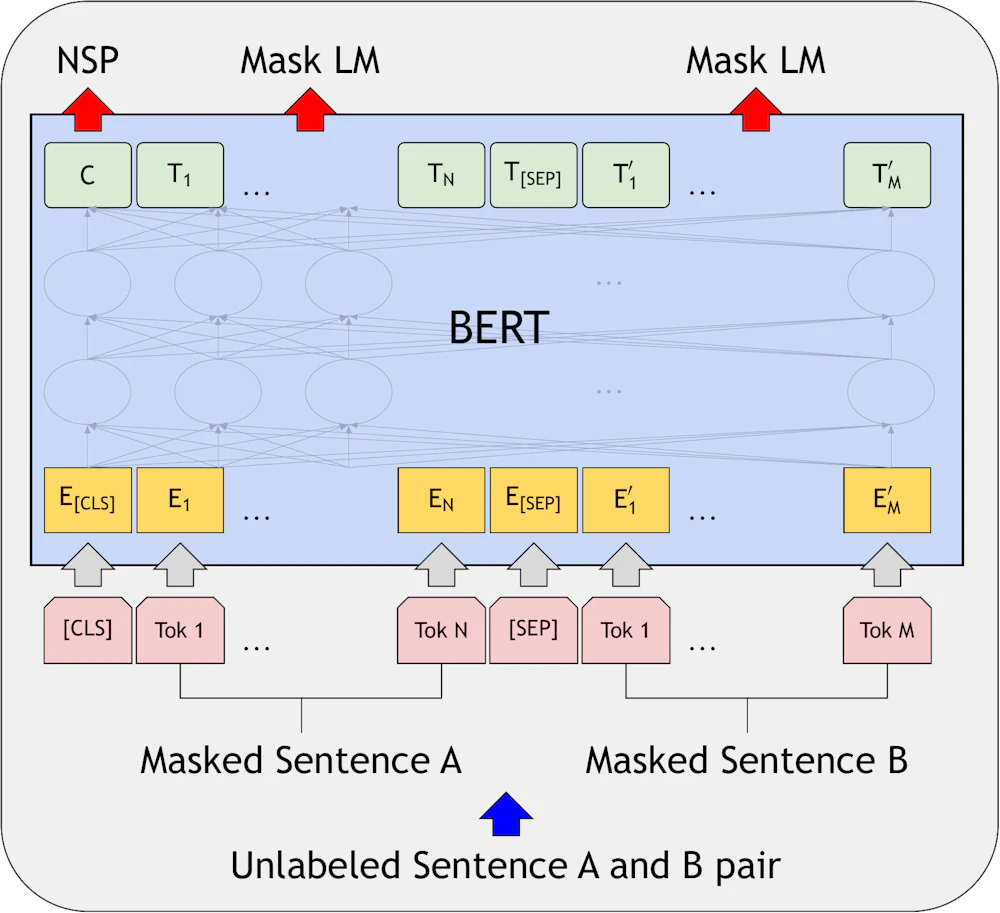
入力
BERT のネットワークの構成は各入力 (および核出力) に関して対称的な構造になっており、特定の順序は存在しません。もちろん各単語の位置は重要ですので、BERT では入力の各トークン (embedded vector) に対し、文章内での位置を示す重みを加えます (Position Embeddings)。また二つの文章を入力する場合には、各トークンがどちらに属すかを示すための重みも加えます (Segment Embeddings)。
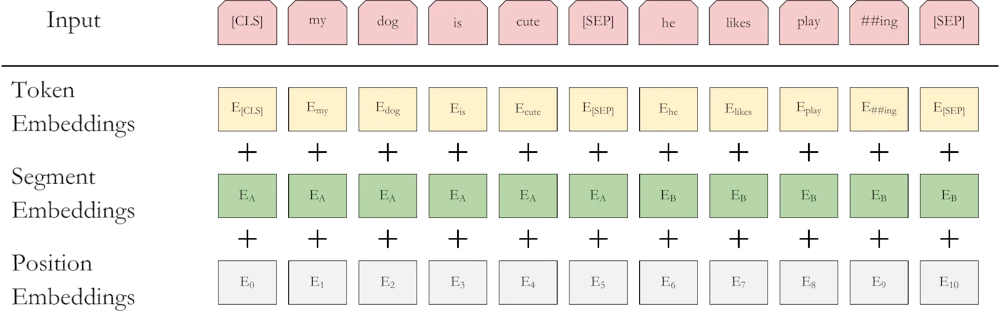
事前学習
BERT は次の二種類のタスクで事前学習を行います。- マスク付き言語モデル
- 基本的に入力と同じものを出力するように学習させるのですが、その際 15% のトークンは特別なトークン [MASK] で置き換えてしまいます。[MASK] に対応する出力が置き換える前の単語になるように学習させます。
- Next Sentence Prediction
- センテンス A と B を、50% は実際に A の次に B が来るケース (IsNext) で、残りの 50% は B をランダムに選んだケース (NotNext) で学習させます。
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
- センテンス A と B を、50% は実際に A の次に B が来るケース (IsNext) で、残りの 50% は B をランダムに選んだケース (NotNext) で学習させます。
ファインチューニング
具体的に個々のタスクで BERT をどのようにファインチューニングしていくのかを見ていきましょう。
Single Sentence Classification Tasks
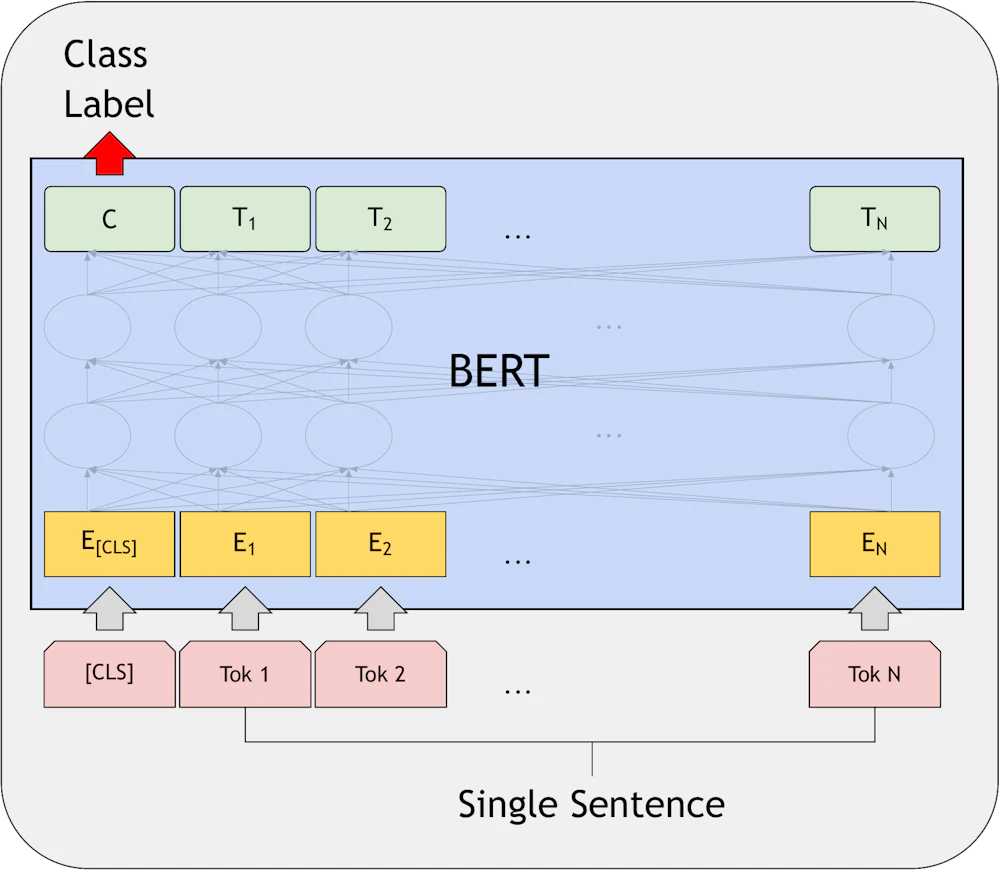
BERT への入は、必ず先頭に [CLS] という特別なトークンを、続けて各単語のトークンを並べます。BERT からの出力は各トークンの文章中でのコンテキストを反映した値となります。[CLS] トークンは文章中に決して表れませんので文書全体のコンテキストと解釈することができるのです。
Sentence Pair Classification Tasks
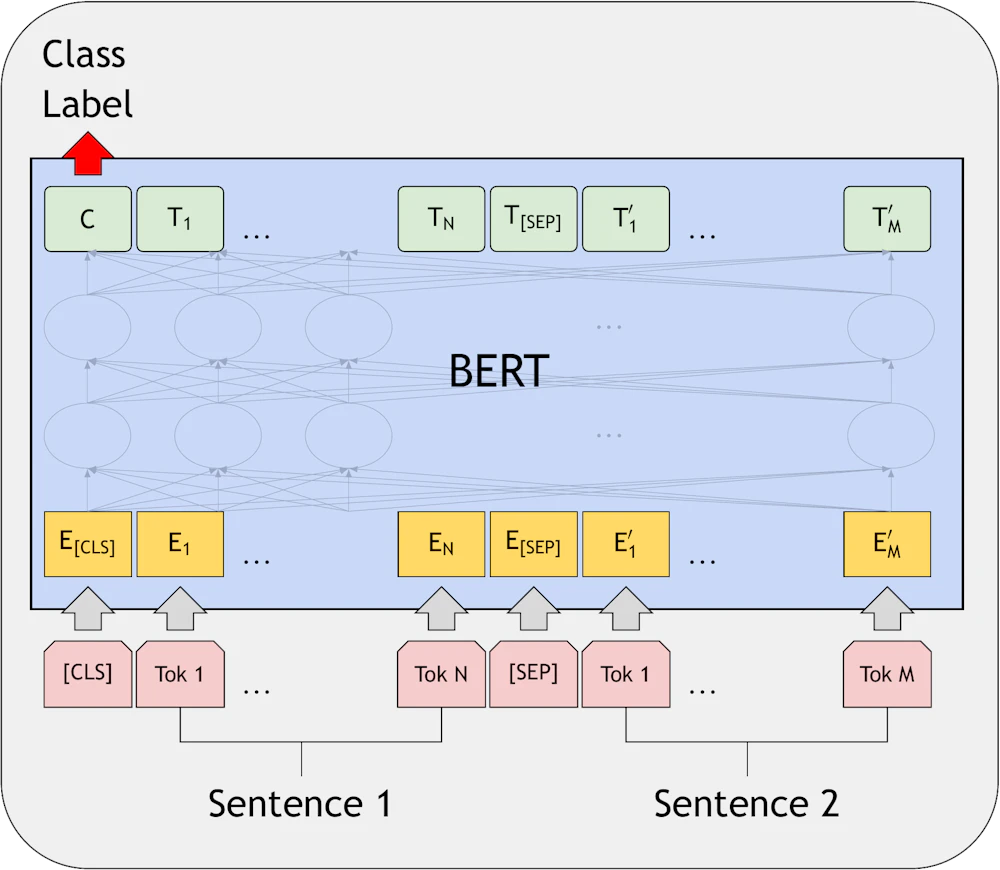
二つの文を分類するタスクでは、それぞれの文の各単語に対応するトークンを [CLS]、Sentence 1 のトークン、[SEP]、Sentence 2 のトークンという並びにして BERT に入力します。ここでも [CLS] トークンに対応する出力が適切なラベルに対応するよう学習させます。
Question Answerring Tasks
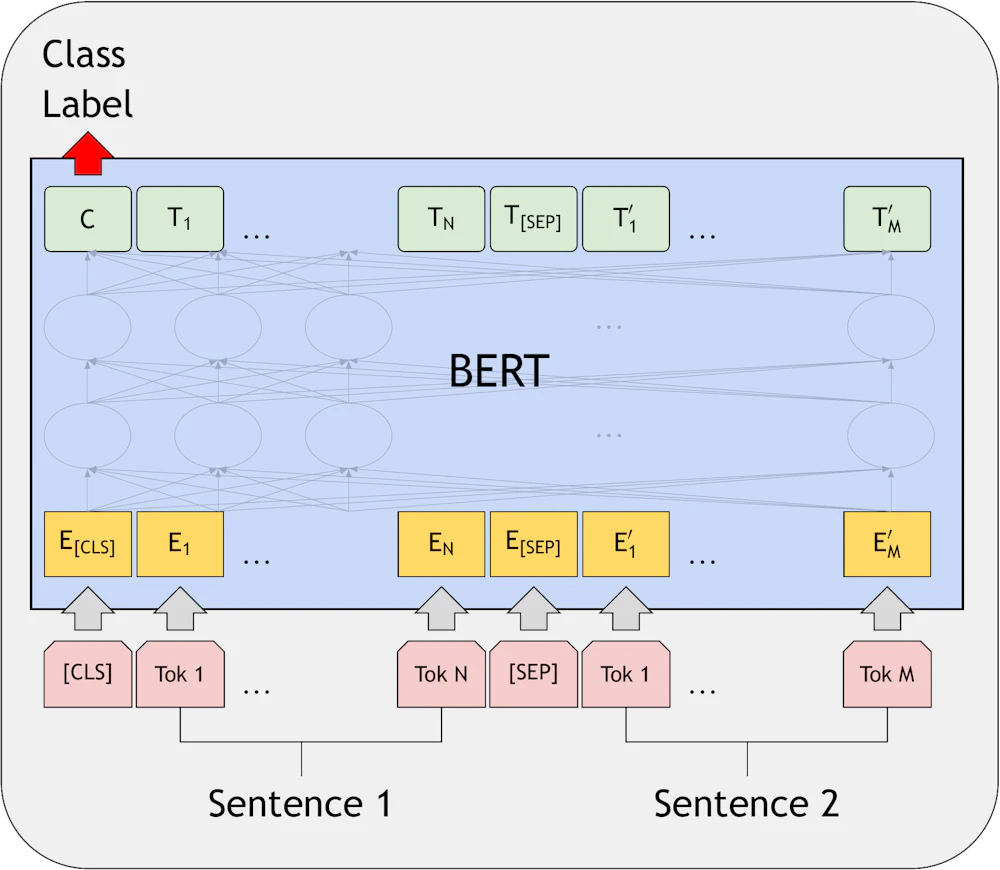
質問に対する回答を生成するタスクでは質問とそのコンテキストとなるパラグラフを入力して、回答に対応したトークンが出力されるよう学習させます。
Single Sentence Tagging Tasks
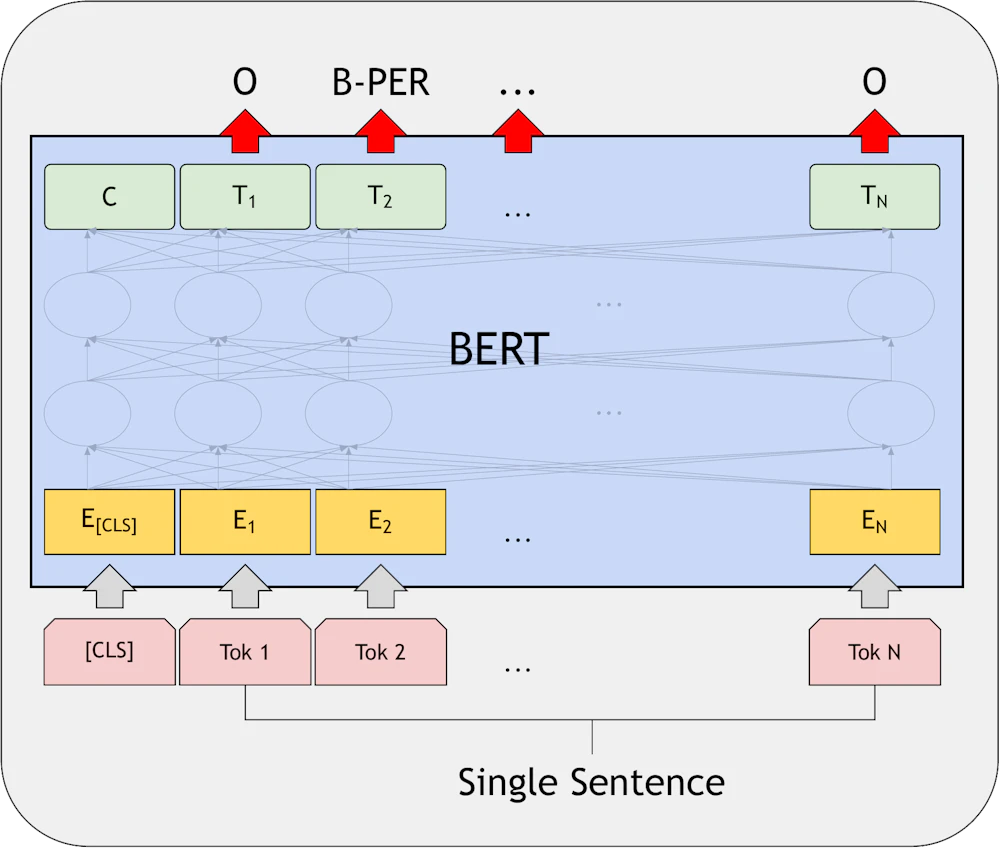
このタスクでは出力がコンテキストに応じたタグとなるように BERT を学習させます。
まとめ
Deep Learning による自然言語処理で BERT が登場するまでの流れと BERT の特長を説明してきました。
BERT は自然言語処理に於いても画像処理と同じく、事前学習済みのニューラルネットをファインチューニングすることにより様々なタスクがこなせることを示した点で画期的なモデルです。
弊社でも BERT を使ったサービスを実装しています。
より詳しい説明
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
The Illustrated Transformer
https://jalammar.github.io/illustrated-transformer/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
https://jalammar.github.io/illustrated-bert/
作って理解する Transformer / Attention
https://qiita.com/halhorn/items/c91497522be27bde17ce
参考文献
Tomas Mikolov, Kai Chen, Greg Corrado, & Jeffrey Dean. (2013).
Efficient Estimation of Word Representations in Vector Space.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2017).
Attention Is All You Need.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, & Kristina Toutanova. (2019).
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
小川 雄太郎 (2019).
PyTorch による発展ディープラーニング, ISBN 4839970254.
Sudharsan Ravichandiran (2021).
Getting Started with Google BERT: Build and train state-of-the-art natural language processing models using BERT, ISBN 1838821597.
近江崇宏, 金田健太郎, 森長誠, 江間見亜利 (2021).
BERT による自然言語処理入門. ISBN 427422726X.